
밍경송의 E.B
머신 러닝과 딥러닝의 차이 본문
갑자기 서점에 갔다가? 갑자기 서지영님의 <딥러닝 파이토치 교과서>를 읽으면서 딥러닝을 공부해보기로 했다.,
논문 분석에 어떤 알고리즘에 대한 이해가 필요한지 잘 몰라서 일단 냅다 파보기로 다짐 ^5^
인공지능 관련 공부가 완전히 처음인 나에게는 조금 버거울 수 있지만,
꼼꼼하게 공부하고 기록해두면 앞으로 어느 길로 가든 많은 도움이 될 것 같다 .. 피스.. 🦉
머신 러닝과 딥러닝의 차이
인공지능에 대해 공부하려면, 먼저 그 구현방법인 머신러닝과 딥러닝의 차이를 알아야 한다. 솔직히 이 장을 읽고나서도 구분이 좀 아리까리하긴 한데,, 명확한 차이점이 존재하기 때문에 정리하고 나면 더 도움이 될 것이라 생각한다.

머신러닝과 딥러닝 모두, 학습 모델을 제공하여 데이터를 분류할 수 있는 기술이지만 둘의 '접근 방식'에 차이가 존재한다.
- 머신러닝은 주어진 데이터를 인간이 먼저 처리(전처리) 하는 과정이 필요함.
why? 머신 러닝은 데이터의 특징을 스스로 추출하지 못하기 때문.
how? 사람이 인지하는 데이터를 컴퓨터가 인지하는 데이터로 변환해주는 작업을 거쳐야 함.
: 데이터별로 어떤 특징이 있는지 찾아서 이것을 벡터로 변환.
- 딥러닝은 전처리 과정을 생략할 수 있음. 컴퓨터가 '신경망'을 이용해 스스로 분석한 후 해답을 찾음.
각각에 대해 좀 더 자세히 알아보잣!
머신 러닝
머신러닝은 크게 1 학습 단계 → 2 예측단계로 나뉘는데,
학습 단계의 결과로 생성된 모형(모델)에 예측단계에서 새로운 데이터를 적용하여 결과를 예측한다.
*여기서 데이터란, 모델을 만드는 데 사용하는 것으로 실제 데이터 특징이 잘 반영되고 + 편향되지 않은 훈련데이터를 확보하는 것이 중요함.
데이터셋은 훈련 데이터와 테스트 데이터으로 분리해서 사용되고, 훈련 데이터셋 중 일부를 검증 데이터셋으로 사용하기도 함.
* 이때 '모델'은 아래의 과정을 반복하여 주어진 문제를 가장 잘 풀 수 있는 모델을 찾음.
<머신 러닝 학습 알고리즘>
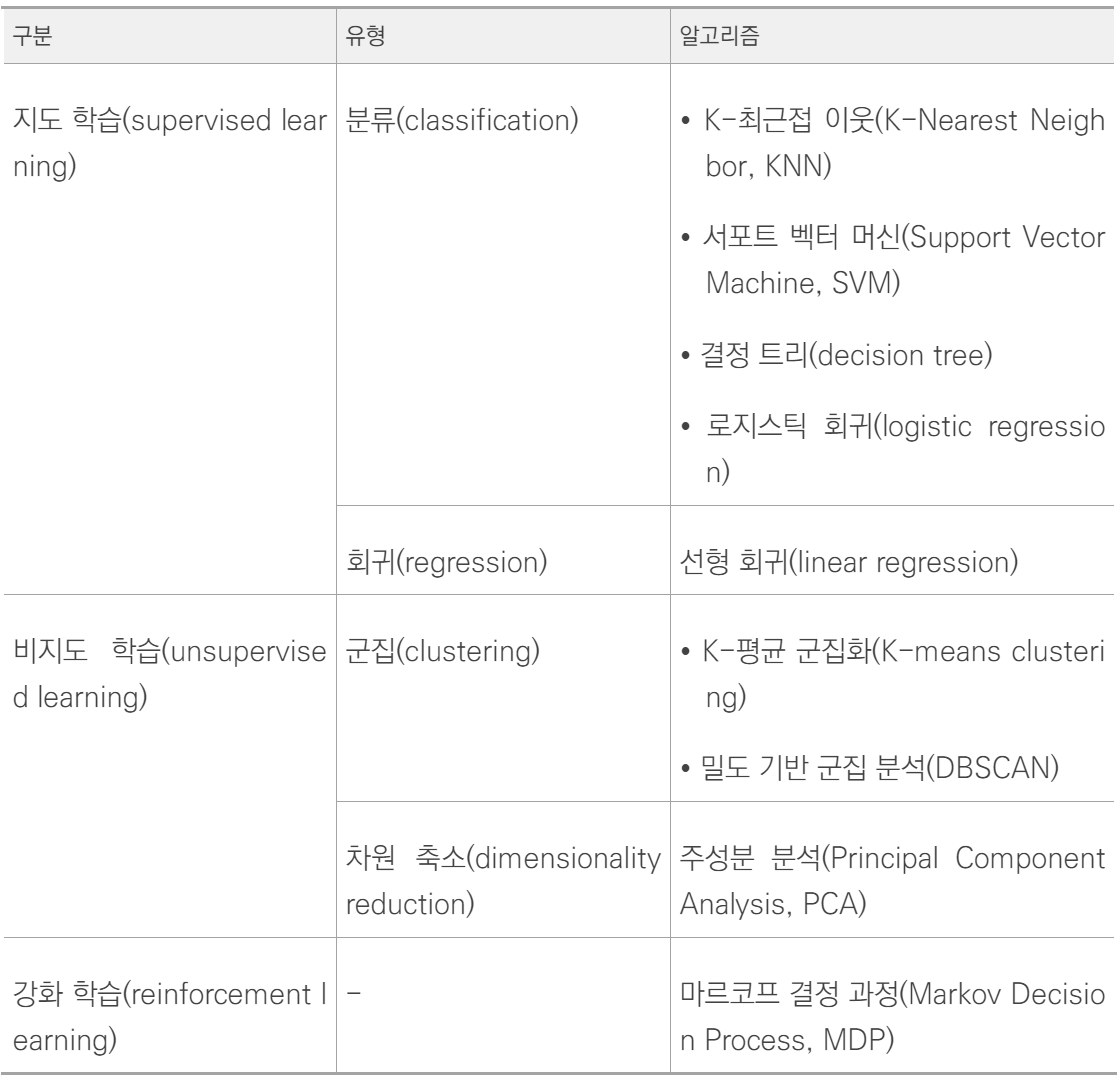
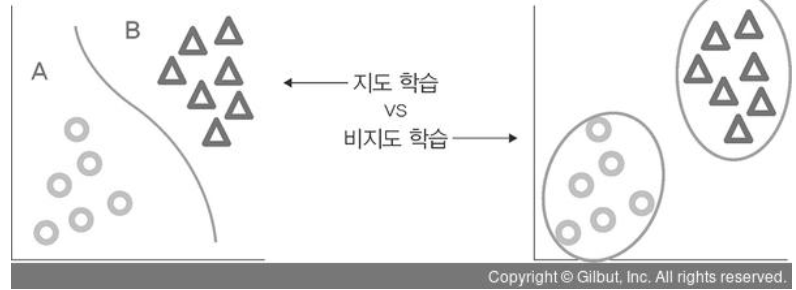
- 지도 학습 : 정답이 무엇인지 컴퓨터에 알려주고 학습시키는 방법
- 비지도 학습 : 정답을 알려주지 않고, 특징이 비슷한 데이터를 클러스터링(범주화)하여 예측하는 방법
- 강화 학습: 자신의 행동에 대한 보상을 받으며 학습을 진행하는 방식.
게임의 에이전트 같은 느낌.. 인가보다
딥러닝
인간의 뇌!를 기초로 하여 설계한(신경망 원리를 모방한) 머신 러닝 방법의 일종
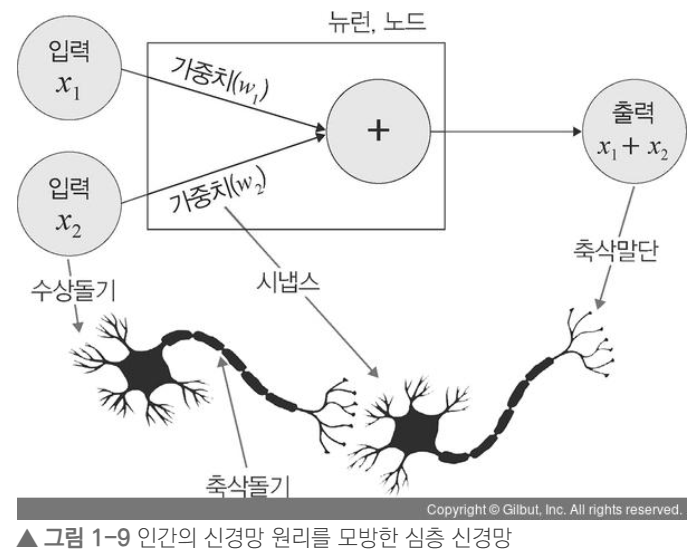
인간의 뇌는 엄청난 수의 뉴런과 시냅스로 구성 ..되어 있고 이것에 착안하여 컴퓨터에 이 개념을 적용했다고 한다.
<딥러닝의 학습과정>
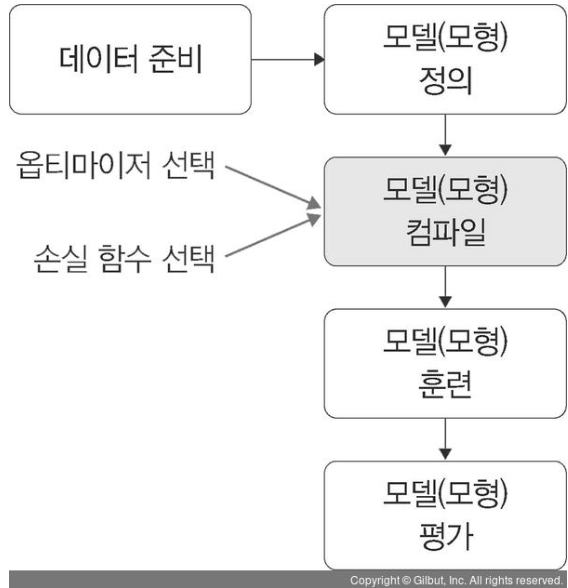
- 데이터 준비 : 책에서는 파이토치나 케라스에서 제공되는, 이미 전처리가 완료된 데이터를 추천함. + 캐글의 공개 데이터
- 모델 정의 : 신경망을 생성하는 단계 *은닉층의 개수가 많을 수록 성능이 좋아짐 but 과적합 발생 확률도 높아짐
- 모델 컴파일 : 활성화 함수(입력 신호가 일정 기준 이상이면 출력 신호로 변환하는 함수), 손실 함수(모델의 출력값과 사용자가 원하는 출력 값의 차이[오차]를구하는 함수), 옵티마이저(손실함수를 기반으로 네트워크 업데이트 방법 결정) 를 선택하는 단계
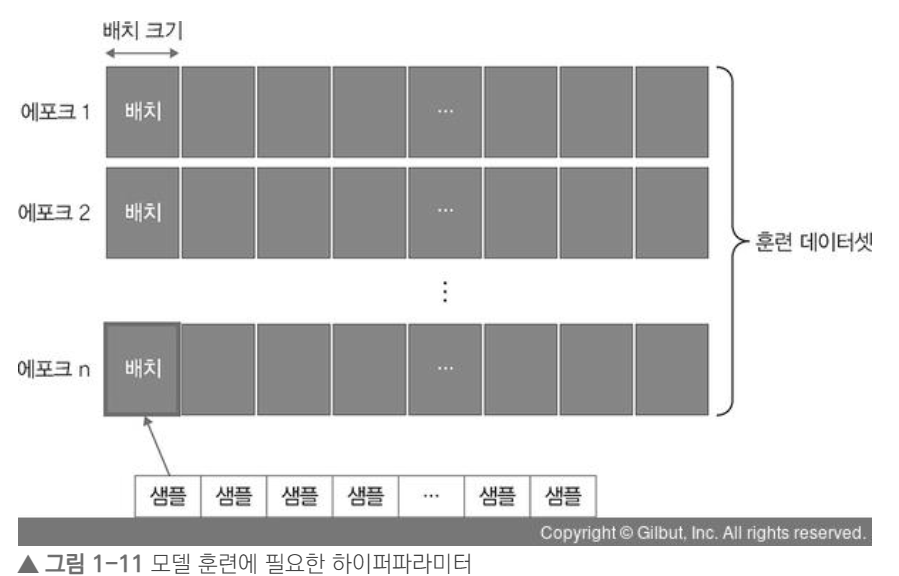
- 모델 훈련 : 한 번에 처리할 데이터 양 지정 *처리할 양이 많아지면 속도가 느려지겠지 ..
전체 훈련데이터셋에서 일정한 묶음으로 나누어 처리할 수 있는 '배치' 와 훈련 횟수인 '에포크' 선택이 중요함.
- 모델 예측 : 검증 데이터셋을생성한 모델에 적용하여 실제 예측을 진행해 보는 단계
<신경망과 역전파>
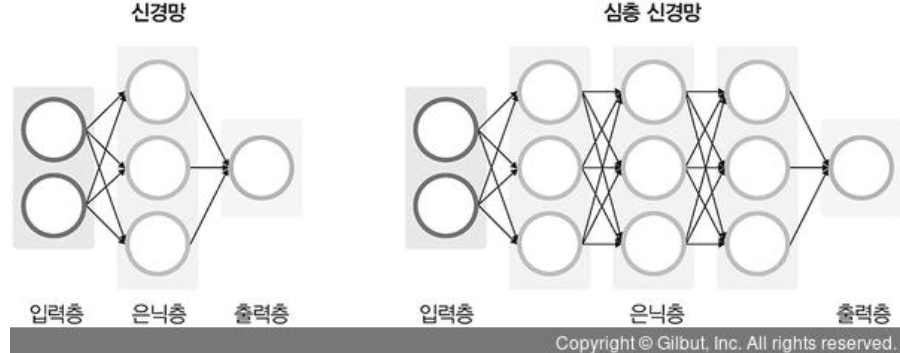
딥러닝은 데이터셋의 어떤 특성들이 중요한지 스스로에게 가르쳐줄 수 있는 '심층신경망'을 사용함.
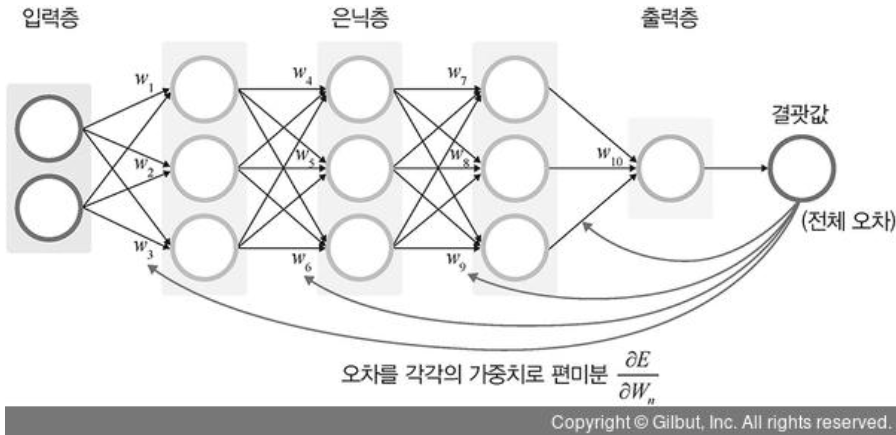
또한, 가중치 값을 업데이트하기 위한 '역전파'가 중요함.
무슨 편미분 어쩌고 하길래 겁먹었는데 ,, 파이토치를 이용하면 이걸 자동으로 해준다고 한다. 헤헷
<딥러닝 학습 알고리즘>
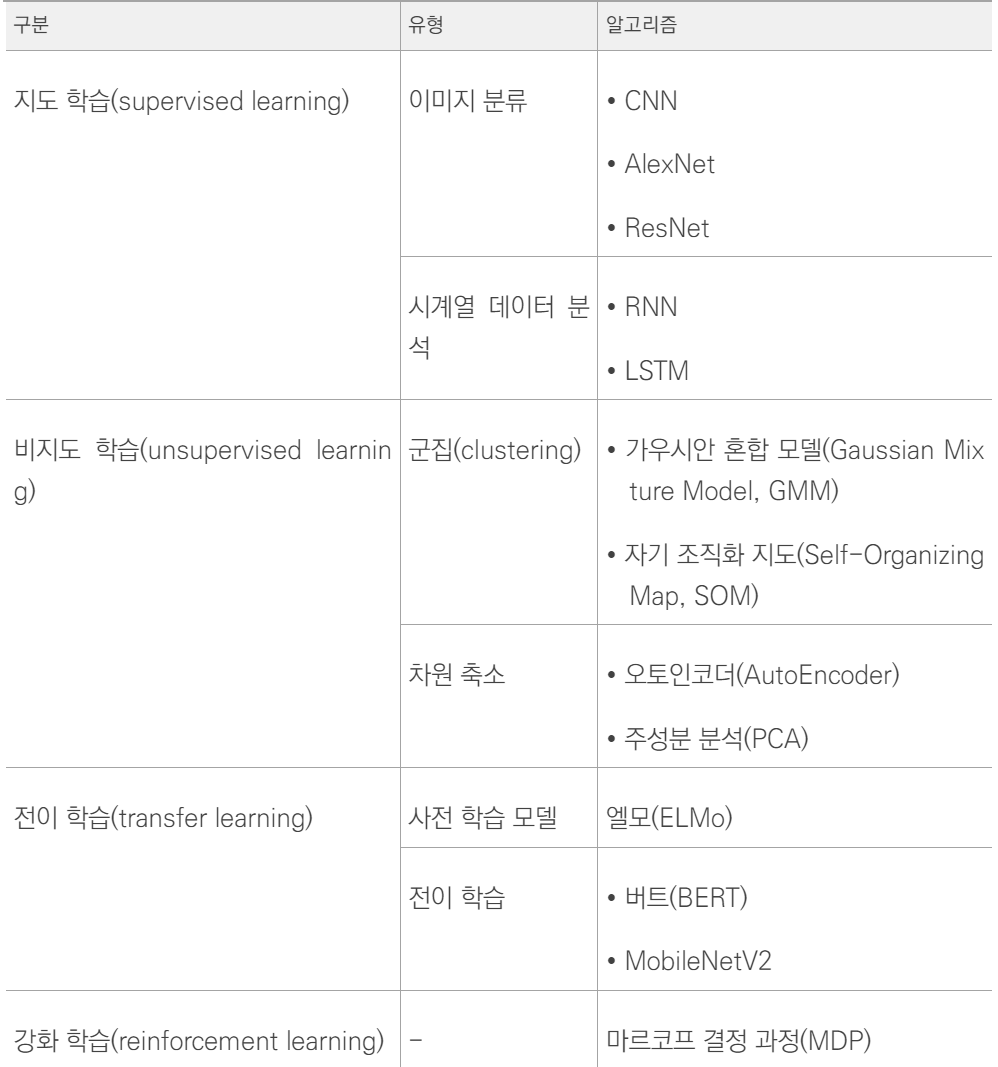
- 지도 학습
CNN(합성곱 신경망) : 이미지 분류(이미지가 어떤 클래스에 속하는지), 이미지 인식(사진을 분석하여 그 안에 있는 사물을 인식하는 것), 이미지 분할(영상에서 사물이나 배경 등 객체 간 영역을 구분) 에 사용
RNN(순환 신경망) : 주식 데이터와 같이 시간에 따른 데이터.,시계열 데이터를 분류할 때 사용
*역전파 과정에서 기울기 소멸의 문제 발생
LSTM : RNN의 문제 개선을 위해 게이트 3개를 도입한알고리즘.
- 비지도 학습
워드임베딩 : 자연어를 벡터로 변환할 때 이용되는 기술 (워드투벡터, 글로브 등)
군집 : 아무런정보가 없는 상태에서 데이터를 분류하는 방법 (머신 러닝과 딥러닝 함께 사용)
- 전이 학습 : 사전 학습 모델을 가지고, 우리가 원하는 학습에 미세 조정 기법을 이용하여 학습시키는 방법