
밍경송의 E.B
파이토치를 이용해 간단 분류 및 회귀 모델 구현하기 본문
오늘은 책에서 제공하는 예제데이터셋과 코드로 간단한 파이토치 실습을 진행해봤숩니다.
저는 anaconda를 통해 가상환경을 만들어서, vscode를 사용하여 작업했습니다.
car_output_예측하기
목차
범주형 데이터 전처리
예제 데이터셋은 다음과 같이 구성되어있었다. 여기서 output은 차 상태로 unacc, acc, good, vgood 중 하나의 값을 가진다.
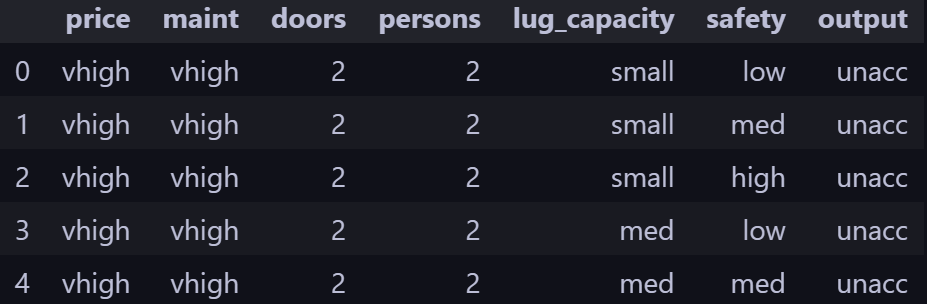
책에서는 1(price)~ 6(safety) 의 정보를 이용해 7(output)을 예측하는 모델을 구현하고자 했다.
데이터셋을 보면, 데이터가 문자와 숫자로 구성되어 있는 것을 확인할 수 있는데, 컴퓨터는 단어를 인식하지 못하기 때문에 단어를 벡터(혹은 숫자 혹은 텐서)로 바꿔주는 임베딩 처리가 필요하다.
전처리를 하기 위해서는 먼저 주어진 데이터의 형태를 파악하고, 숫자로 변환해주어야 하는데, 우리가 지금 다루고 있는 데이터는 '범주형 데이터' 기 때문에 이것을 텐서로 변환해주는 절차를 알아보고자 한다.
1-1. 데이터를 범주형 타입으로 변환하기
categorical_columns = ['price', 'maint', 'doors', 'persons', 'lug_capacity', 'safety']
for category in categorical_columns :
dataset[category] = dataset[category].astype('category') #astype() : 데이터를 범주형으로 변환
1-2. 범주형 데이터를 숫자(np 배열)로 변환하기
price = dataset['price'].cat.codes.values #범주형 데이터를 숫자(np 배열)로 변환하기 위해 cat.codes 사용
maint = dataset['maint'].cat.codes.values
doors = dataset['doors'].cat.codes.values
persons = dataset['persons'].cat.codes.values
lug_capacity = dataset['lug_capacity'].cat.codes.values
safety = dataset['safety'].cat.codes.values
categorical_data = np.stack([price, maint, doors, persons, lug_capacity, safety], 1)
#np.stack을 이용해 2개 이상의 객체를 합침
*넘파이 객체를 합칠 때는 np.stack와 np.concatenate를 모두 사용할 수 있다.
이때 둘의 차이는, np.stack의 경우는 배열들을 새로운 축으로 합쳐주지만, np.concatenate는 선택한 축을 기준으로 두 개의 배열을 연결해준다는 점에서 차이가 있다.
위의 결과를 출력해보면 아래와 같다.

1-3. torch 모듈을 이용하여 배열을 텐서로 변환
categorical_data = torch.tensor(categorical_data, dtype=torch.int64)
결과는 아래와 같다.

1-4. 레이블로 사용할 칼럼도 텐서로 변환
outputs = pd.get_dummies(dataset.output) #get_dummies : 가변수(문자를 0,1로) 만들어주는 함수
outputs = outputs.values
outputs = torch.tensor(outputs).flatten()
print(categorical_data.shape)
print(outputs.shape)
get_dummies()를 적용하면, 데이터에 있었던 문자를 숫자(0,1)로 바꾸어서 새로운 배열을 생성해준다.
예를 들어보자.
male 또는 female의 값을 가지는 gender라는 col가 존재한다.
| gender | |
| 0 | male |
| 1 | female |
| 2 | female |
여기에 get_dummies()를 적용하면, 다음과 같은 결과가 나온다.
| gender_male | gender_female | |
| 0 | 1 | 0 |
| 1 | 0 | 1 |
| 2 | 0 | 1 |
결과는 다음과 같다.

1-5. 단일 숫자의 넘파이 배열을 N차원으로 변환하기
categorical_column_sizes = [len(dataset[column].cat.categories) for column in categorical_columns]
categorical_embedding_sizes = [(col_size, min(50, (col_size+1)//2)) for col_size in categorical_column_sizes]
# (칼럼 고유의 값 수, 차원의 크기)로 출력
print(categorical_embedding_sizes)
높은 차원의 임베딩일 수록 단어 간의 세부적인 관계를 잘 파악할 수 있기 때문에 N차원으로 변환하는 과정을 거친다.
이때 N(임베딩 크기)를 정하는 규칙은 없지만, 보통 col의 고유 값 수를 2로 나누는 것을 많이 사용한다고 한다.
예를 들어, price의 경우 고유 값이 4개기 때문에, 임베딩 크기는 2가 되는 것이다.
결과를 출력하면 아래와 같다.

다음으로, 데이터셋을 훈련용과 테스트용으로 분리하는 작업을 거쳐야 한다.
2. 데이터셋 분리
전체의 20%를 테스트 용도로 사용한다고 가정하고 코드를 구현한다.
total_records = 1728
test_records = int(total_records * .2)
categorical_train_data = categorical_data[:total_records - test_records]
categorical_test_data = categorical_data[total_records - test_records:total_records]
train_outputs = outputs[:total_records - test_records]
test_outputs = outputs[total_records - test_records:total_records]
이렇게 하면 훈련 데이터의 레코드 수가 1383, 테스트 데이터의 레코드 수가 345개로 나눠진다.
이제 데이터에 대한 준비는 완료됐으므로, 모델의 네트워크를 생성하면 된다.
3. 모델 생성
3-1. 모델 네트워크 생성
class Model(nn.Module):
def __init__(self, embedding_size, output_size, layers, p=0.4): #모델에서 사용될 파라미터와 신경망 초기화
super().__init__()
self.all_embeddings = nn.ModuleList([nn.Embedding(ni, nf) for ni, nf in embedding_size])
self.embedding_dropout = nn.Dropout(p)
all_layers = []
num_categorical_cols = sum((nf for ni, nf in embedding_size))
input_size = num_categorical_cols
for i in layers: # 각 계층을 all_layers 목록에 추가
all_layers.append(nn.Linear(input_size, i)) #선형변환
all_layers.append(nn.ReLU(inplace=True)) #활성화 함수
all_layers.append(nn.BatchNorm1d(i)) #정규화
all_layers.append(nn.Dropout(p)) # 과적합 방지
input_size = i
all_layers.append(nn.Linear(layers[-1], output_size))
self.layers = nn.Sequential(*all_layers)
def forward(self, x_categorical): # 학습 데이터를 입력받아 연산 진행
embeddings = []
for i,e in enumerate(self.all_embeddings):
embeddings.append(e(x_categorical[:,i]))
x = torch.cat(embeddings, 1)
x = self.embedding_dropout(x)
x = self.layers(x)
return x
주석을 달아두긴 하였으나 아직 각 함수나 계층에 대한 이해가 부족하다고 느껴진닷.. 예제를 많이 실행해보면 좀 괜찮아질 거 같다 🥲
네트워크 계층의 생성을 완료했으면, 모델 훈련을 위한 Model 클래스의 객체를 생성해야 한다. 이때, 범주형 칼럼의 임베딩 크기, 출력 크기, 은닉층의 뉴런, 드롭 아웃을 지정하여 전달해야 한다.
*은닉층의 뉴런을 다른 크기로 지정해 테스트 해보자.
3-2. 모델 클래스의 객체 생성
model = Model(categorical_embedding_sizes, 4, [200,100,50], p=0.4)
model을 출력해보면 다음과 같다.

다음으로, 모델의 파라미터를 정의하고, CPU 혹은 GPU 사용을 지정해주면 학습을 위한 준비가 완료된다.
3-3. 모델의 파라미터 정의
loss_function = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr= 0.001)
책에서는 손실 함수로 크로스 엔트로피를 사용하였고, 옵티마이저로 Adam을 사용하였다.
3-4. CPU 혹은 GPU 사용 지정
if torch.cuda.is_available():
device = torch.device('cuda')
else:
device = torch.device('cpu')GPU가 있다면 GPU를 사용하는 것이 좋기 때문에 각자 환경에 따라 지정되도록 코드를 짜준다.
gpu 설치하다가 에러를 겪었기 때문에,, 우선은 CPU로 작업하고자 한다.
이제 준비된 데이터로 모델을 학습시킨다.
4. 모델 학습 및 예측
4-1. 모델 학습
epochs = 500
aggregated_losses = []
train_outputs = train_outputs.to(device=device, dtype=torch.int64)
for i in range(epochs): #500회 반복. 각 반복마다 손실함수가 오차를 계산함
i += 1
y_pred = model(categorical_train_data).to(device)
single_loss = loss_function(y_pred, train_outputs)
aggregated_losses.append(single_loss) #반복될 때마다 오차를 aggre_에 추가
if i%25 == 1:
print(f'epoch: {i:3} loss: {single_loss.item():10.8f}')
optimizer.zero_grad()
single_loss.backward() #가중치 업데이트를 위해 손실함수의 backward() 호출
optimizer.step() #옵티마이저 함수의 step() 메서드를 이용하여 기울기 업데이트
print(f'epoch: {i:3} loss: {single_loss.item():10.10f}') #오차가 25 에포크마다 출력됨
여기서 에포크(epoch)란 전체 데이터셋이 신경망을 통과한 횟수를 의미한다.
그러니까 총 500번 통과하는 거고, 25 에포크마다 오차를 출력하도록 설계되었다.
결과는 아래와 같다.

이제 20%의 테스트 데이터셋으로 모델을 예측하여, 이 데이터셋에 대한 손실 값을 확인할 수 있다.
4-2. 테스트 데이터셋으로 모델 예측
test_outputs = test_outputs.to(device=device, dtype=torch.int64)
with torch.no_grad():
y_val = model(categorical_test_data).to(device)
loss = loss_function(y_val, test_outputs)
print(f'Loss: {loss:.8f}')
출력 결과 Loss : 0.54982191 가 도출되었다.
*이 값은 훈련 데이터셋에서 도출된 손실 값과 비슷하기 때문에 과적합은 발생하지 않았다고 판단할 수 있겠다.
4-3. 모델의 예측 확인
실제값과 모델에 의해 예측된 값을 비교하여 두 값의 차이를 구함으로써 모델이 예측을 맞게 했는지 확인할 수 있다.
실제값 - 예측값 = 0 이 되면 오차가 없는 것으로 볼 수 있다.
**근데 이 부분은 코드랑 같이 봐도 잘 이해가 안돼서 .. 다른 예제로 이해해야 될 것 같다.
print(y_val[:5]) # 각 예측에는 4개의 값이 포함(outputsize를 4로 지정)
y_val = np.argmax(y_val.cpu().numpy(), axis=1)
print(y_val[:5])

이렇게 하면 y_val에서 처음 5개의 값이 출력되는데,인덱스가 0인 값이 인덱스가 1인 값보다 크므로 처리된 출력이 모두 0이 된다.
=> [0, 0, 0, 0, 0]
4-4. 테스트 데이터셋을 이용한 정확도 확인
import warnings
warnings.filterwarnings('ignore')
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score
test_outputs=test_outputs.cpu().numpy()
print(confusion_matrix(test_outputs,y_val))
print(classification_report(test_outputs,y_val))
print(accuracy_score(test_outputs, y_val))
결과는 다음과 같다.

코드에서 사용된 성능 평가 지표에 대해 간단하게 살펴보자.

- True Positive(TP) : 실제 True인 정답을 True라고 예측 (정답)
- False Positive(FP) : 실제 False인 정답을 True라고 예측 (오답)
- False Negative(FN) : 실제 True인 정답을 False라고 예측 (오답)
- True Negative(TN) : 실제 False인 정답을 False라고 예측 (정답)
- 정확도(Accuracy) : 전체 예측 건수 중 정답을 맞힌 건수의 비율
- 재현율(Recall) : 실제로 정답이 1이라고 할 때, 모델도 1로 예측한 비율( only True positive)

- 정밀도(Precision) : 모델이 1이라고 예측한 것 중에 실제로 정답이 1인 비율

일반적으로, 재현율과 정밀도는 서로 반비례하는 관계라고 한다. 그런데, 이러한 문제(trade-off)를 해결하기 위해 정밀도와 재현율의 조화 평균을 이용한 것이 바로 F1- score 평가이다.
- F1-스코어(F1-score)

전체 코드와 결과는 github에서 확인하실 수 있습당 !