
밍경송의 E.B
End-to-End TTS(Text-To-Speech)의 이해 본문
감자인 상태로 졸업프로젝트에 던져진 3망년..!
첫 대면 팀플을 했던 동기들이랑 졸업프로젝트까지 함께하게 되었숩니다.
인공지능의 ㅇ자도 모르는 제가 .! TTS 기술을 활용한 프로젝트를 기획하게 되었습니다.
TTS에 대해서 아는 것이 없기 때문에 기본적인 공부가 필요했는데요.
많은 TTS 모델들 중 최신 모델이면서 성능이 뛰어난 VITS2 모델에 관한 논문을 읽으며 음성 분야에 대한 기본 지식을 쌓고자 했습니다.
아래는 제가 읽은 논문의 제목과 저자, 그리고 논문의 원본입니다.
모든 내용의 저작권과 출처는 아래 논문에 있음을 밝힙니다.
< Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech>
by Jaehyeon Kim, Jungil Kong, Juhee Son
✨Abstract
***Two-stage TTS 시스템**
: 텍스트에서 중간 표현 생성 ( 텍스트 입력을 중간 텍스트로 변환 - *텍스트의 의미, 발음*과 관련된 정보들을 포함)
: 중간 표현에서 음성 생성 ( 중간 표현을 사용하여 실제 음성 생성 - *음성 합성 및 음성 품질 조절*이 이루어짐)
: 이 연구에서는 현재의 Two-stage TTS 시스템보다 더 자연스러운 소리를 생성하는 Parallel end-to-end TTS method 을 제시함.
- **Variational inference(변분 추론)**과 **Normalizing flows(정규화 흐름)**을 활용하며, 생성 모델의 표현 능력을 향상시키기 위해 Adversarial Learning를 채택 + 입력 텍스트에서 다양한 리듬으로 음성을 생성하기 위한 **Stochastic duration predictor(확률적 지속 시간 예측자)**를 제안.
- 최근 몇 년 동안 단일 단계 훈련과 병렬 샘플링을 가능하게 하는 여러 End to end 텍스트에서 음성으로 변환하는 모델이 제안되었지만, 이러한 모델은 현재의 Two-stage TTS 시스템과는 맞지 않음. (음성 샘플의 품질에서 뒤떨어짐)
*Variational Inference(변분 추론) : 확률 분포의 추론과 학습을 수행하는 확률적 그래픽 모델과 관련된 통계적 기법; 복잡한 확률 모델에서 확률 변수와 파라미터의 불확실성을 측정하고 추론하는 데 유용함.
*Normalizing flows(정규화 흐름) : 확률 분포를 변환하고 모델링하기 위한 확률적 그래픽 모델의 기술 중 하나; Variational Inference( 과 같은 확률적 그래픽 모델과 연결하여 불확실성 모델링 및 확률 분포 모델링에 널리 사용됨.
* Stochastic duration predictor(확률적 지속 시간 예측자) : 음성 합성 시스템에서 사용되는 기술 중 하나로, 입력 테스트의 각 음소 또는 음절이 얼마 동안 지속되는지 예측하는 모델;
✨ Instruction
: TTS시스템은 여러 구성 요소를 통해 주어진 텍스트에서 원시 음성 파형을 합성하는 것. 딥 뉴럴 네트워크의 신속한 발전으로 인해 TTS 시스템 파이프라인은 텍스트 정규화와 같은 텍스트 전처리를 제외하고 두 단계 생성 모델링으로 단순화. (앞에서 말한 *Two-stage TTS) 두 단계 파이프라인 각각의 모델이 독립적으로 개발됨.
*Neural network-based autoregressive TTS systems (신경망기반 자기 회귀 TTS 시스템→ 딥 뉴럴 넼웤 사용)은 현실적인 음성을 합성하는 능력 good, but 순차적 생성 과정 때문에 modern parallel processor 활용에 어려움 있음.
ㄴ순차적 생성 과정 : 음성을 생성할 때 이전 단계의 출력을 이용하여 현재 단계의 출력을 예측하고, 이를 반복하여 전체 음성을 생성. 음성을 한 프레임 또는 샘플링 단위로 생성하는 과정 포함.
→ 문제점 극복 + 합성 속도 향상을 위해 Non-autoregressive methods(비자기 회귀 방법) 제안됨.
*Text-to-Spectrogram generation step(텍스트에서 스펙트로그램을 생성하는 단계)에서는 Pre-trained autoregressive teacher networks(사전 훈련된 자기 회귀 교사 네트워크)로부터 Attention maps(주의 맵)을 추출하는 시도를 통해 텍스트와 스펙트로그램 간의 정렬을 학습하기 어려운 문제를 완화하려 함.
ㄴText-to-Spectrogram generation step(텍스트에서 스펙트로그램을 생성하는 단계) : 텍스트에서 음성 파형을 만들기 위해 중간 단계로 스펙트로그램(시간에 따른 음성의 주파수 컨텐츠를 시각적으로 표현한 것) 이라는 음성표현으로 생성하는 단계

*Attention maps(주의 맵) : 딥러닝 모델에서 특히 시퀀스 간의 관계를 모델링할 때 사용되는 기술; 음성 인식에서 어떤 음성 신호 부분에 주의해야하는 지 결정하는 등에 사용
*정렬 : 텍스트와 해당 텍스트를 음성으로 변환하는 과정 중에서 어떤 텍스트 부분이 어떤 시간대의 음성 신호와 연결되는지, 어떤 텍스트 단어 또는 구절이 어떤 부분의 음성에 해당하는지 결정하는 것; ex) 안녕하세요 ㅇㅇ님. 에서 각 단어 또는 음절이 언제 발음되는지, 어떤 부분의 음성과 연관이 있는지 정확히 결정해야 함.
더 최근에는, likelihood-based methods(가능도 기반 방법)을 통해 외부 정렬 도구에 대한 의존성 제거(모델 스스로 가능도를 최대화하는 정렬 추정/학습) + target 멜-스펙트로그램의 likelihood 최대화하는 정렬 추정/학습을 통해 속도를 향상시켰다고 함.
ㄴlikelihood-based methods : 주어진 데이터가 특정 확률 분포에서 어떻게 생성될 것으로 예측하는 것이 목표. (가능도 = 주어진 데이터가 주어진 모델에 의해 생성될 확률)
ㄴ멜-스펙트로그램 : 일반적인 스펙트로그램은 주파수 영역을 선형 슼케일로 표시, 멜의 경우는 주파수 영역을 멜 스케일로 표현 (멜 스케일 : 인간의 청각 시스템의 주파수 변환을 모델링한 것, 낮은 주파수에서 더 많으 상세 정보 제공)
Generative adversarial networks (GANs) (- 위에서 설명한 Adversarial Learnging 으로 이해하면 됨) 을 사용하여 음성 합성 분야에서 원시 파형 합성을 달성했지만, two stage TTS 파이프라인은 여러 문제가 존재.
❔여러 문제란,
:Two stage TTS 파이프라인은 앞서 말했듯,
[1) 텍스트 → 중간 표현(ex 멜 스펙트로그램)
2) 중간 표현 → 원시 음성 파형 생성 과정] 이렇게 나눠지는데,
1)에서 생성된 중간 표현을 사용하여 2) 를 훈련하고 조정하기 때문에 모델 간의 의존성, 복잡성이 높아지고, 조정 과정에서 어려움을 겪는다고 함.
=> 그래서 최근 몇 년동안 End-to-End method에 대한 방법이 제안되었음. 이 방법은 학습된 표현을 활용함으로써 성능을 개선할 수 있는 가능성 존재, but 합성 품질은 Two stage TTS를 못 따라감.
( End-to-End method가 성능은 더 높을 수 있더라도, 아직 Two stage method보다 합성 품질(음성의 자연스러움, 발음의 정확성, 억양, 감정 전달 등)이 떨어지는 문제가 있음 )
⚠️ 따라서, 이 연구는 Two stage method보다 더 자연스러운 음성(합성 품질을 높인)을 생성하는 Parallel end-to-end TTS method를 제시함!
→ 이를 위해 Conditional Variational Autoencoder 에 Normalizing flow 적용, 파형 영역에 Adversarial Learnging 을 수행. → one-to-many problem(일대다 문제)를 해결하기 위해 입력 텍스트로부터 다양한 리듬으로 음성을 합성하기 위한 Stochastic duration predictor(확률적 지속 시간 예측자) 를 제안함.
✨ Method
- 2.1 Variation Inference
VITS는 데이터의 특정 조건 c에 대한 잠재 변수 z의 사전 분포 pθ(z|c), 데이터 포인트 x의 우도 함수 pθ(x|z) 및 근사 사후 분포 qφ(z|x)를 사용하여 무차원 마진 로그 우도 데이터 log pθ(x|c)를 최대화하는 조건부 VAE로 표현될 수 있음.
1) 복원 손실 - 복원 손실 대상 데이터 포인트를 멜-스펙토그램을 사용하여, z를 원시 파형 데이터로 변환. → L1 손실 최소화(손실이 낮을 수록 모델이 예측한 멜-스펙토그램과 실제 목표 멜-스펙토그램 간의 차이가 적음)
⇒목표는 입력 데이터를 얼마나 정확하게 멜-스펙토그램으로 나타낼 수 있는가
*상수항 무시한 최대 우도 추정, z 전체를 업샘플링하지 않고, 디코더의 입력으로 부분 시퀀스를 사용 (효율적 End-to-End 훈련)
2) KL-Divergence(클루슐러-라이블러 발산) : 두 확률 분포 간의 차이를 측정하는 지표
입력 조건 c는 텍스트에서 추출한 음소인 ctext와 음소+ 잠재 변수 간의 정렬인 A.
*정렬은 입력 음소가 목표 음성과 얼마나 시간에 맞춰지는지를 나타내는 행렬
⇒ 목표는 사후 인코더에 더 많은 고해상도 정보를 제공하는 것
*선형 스케일 스펙토그램 xlin을 입력으로 사용 → 입력이 멜-스펙토그램이 아니라 선형 스케일 스펙토그램으로 변경됨.
*사전 인코더와 사후 인코더를 매개변수화하기 위해 요소화된 정규분포 사용 , 정규화 플로우 fθ 사용하여 단순 분포를 복잡화 (분포를 더욱 유연하게 만듦)
ㄴ사전 인코더 : 모델이 생성하는 데이터의 특성을 나타내는 변수
ㄴ사후 인코더 : 모델이 실제로 관찰된 데이터에 어떻게 적합한지를 나타내는 변수
- 2.2 Alignment Estimation
1) Monotonic Alignment Search(단조적 정렬 검색)
: 정렬 검색은 음성 합성 및 처리 모델이 텍스트와 음성 간의 관계를 파악하고 정확한 발음 및 발화 속도를 보장하기 위해 필수적인 작업[어떤 단어나 소리가 실제 음성에서 언제 발음되어야 하는가]
: 단조적 정렬 검색은 데이터 가능성을 최대화하는 정렬을 찾는 데 사용되고 이를 표현하는 데 정규화 플로우f로 매개변수화됨.
→ 우리의 목표는 정확한 로그 우도(Log Likelihood)가 아니라 ELBO(증거 하한 한계), MAS(Monotonic Alignment Search) 재정의를 통해 ELBO를 최대화하는 정렬을 찾도록 함.
*로그우도 : 주어진 데이터가 주어진 확률 분포에서 얼마나 가능한지를 나타내는 값의 로그로 주어진 데이터가 모델 또는 분포와 얼마나 일치하는지 평가하는 지
*ELBO : 데이터의 로그 우도를 하한한 값 . 이걸 최대화하면? 모델의 파라미터를 효과적으로 학습하고, 주어진 데이터에 대한 모델의 불확실성을 줄일 수 있음.
*MAS : 입력 텍스트와 대상 음성 간의 정렬을 찾아내기 위한 방법. 이 방법은 가능한 많은 후보 정렬 중에서 데이터의 가능성을 최대화하는 정렬을 찾아냄.
2) DURATION PREDICTION FROM TEXT(텍스트로부터의 지속 시간 예측)
: 텍스트→ 음성의 각 요소(음소)의 지속 시간을 정확하게 예측하는 대신, 확률적인 방법을 사용하여 인간과 유사한 발화 속도와 리듬을 생성함.
how?
확률적 지속 시간 예측기를 설계, Maximum Likelihood Estimation(최대 우도 추정)을 사용하여 훈련함. → but 고차원 변환을 어렵게 만드는 제약 존재
⇒ 문제 해결을 위해 이산 정수의 연속적 변환을 위한 “quantization(변이 해제)” 및 “augmentation(변이 데이터 보강)”을 적용함.
⚠️음소 지속 시간은 확률적 지속 시간 예측기의 역변환을 통해 무작위 노이즈로부터 샘플링되며 그런 다음 정수로 변환!
- 2.3 Adversarial Training
: 적대적 훈련을 도입하여, 디코더 G가 생성한 출력과 원본 음파 y를 구별하는 판별자 D 사용 - 여기서 2가지 종류의 손실 함수(loss successfully) 사용
1) 적대적 훈련을 위한 least-squares loss function (최소 제곱 손실 함수)
2)생성기를 훈련시키기 위한 feature matching loss(피처 매칭 손실)
: VAE의 요소별 복원 손실 대안으로, 판별자의 숨겨진 레이어에서 측정되는 복원 손실
*VAE(Variational Autoencoder) 모델에서 입력 데이터를 재구성하는 과정
: 인코더 → 잠재 변수 샘플링 → 디코더(원래 입력 재구성) → 재구성 손실[모델이 입력 데이터를 재구성하고 원래 데이터와 얼마나 유사한지를 평가하는 데 사용]
⇒ 생성기 향상을 통해 음성 합성 품질 향상, 실제 음성과 유사한 결과 도출
- 2.4 Final Loss
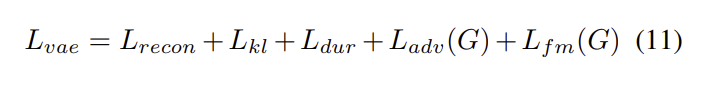
: VAE(Variational Autoencoder)와 GAN(Generative Adversarial Network) 훈련을 결합한 조건부 VAE를 훈련하기 위한 총 손실
- 2.5 Model Architecture
: 제안된 모델의 전반적인 아키텍처는 후방 인코더, 사전 인코더, 디코더, 판별자 및 확률적 지속 시간 예측기로 구성.
✨ Experiments
<활용한 데이터셋>
*LJ Speech 데이터셋 : a public domain speech dataset consisting of 13,100 short audio clips of a single speaker reading passages from 7 non-fiction books.
https://keithito.com/LJ-Speech-Dataset/
-*VCTK 데이터셋 : a speech data uttered by 110 English speakers with various accents.
https://paperswithcode.com/dataset/vctk
- Processing
후방 인코더(Posterior Encoder)의 입력으로 사용할 선형 스펙트로그램은 STFT(Short-time Fourier transform)를 통해 원시 파형에서 얻음.
이때, FFT 크기, window 크기 및 hop 크기는 각각 1024, 1024, 256로 설정.
*국제 음성 국제 음성 표기법(IPA) 시퀀스를 사전 인코더의 입력으로 사용함. 텍스트 시퀀스를 IPA 음소 시퀀스로 변환→ 변환된 시퀀스에는 Glow-TTS의 구현을 따라, 공백 토큰이 삽입함.
-Training
: AdamW 옵티마이저를 사용하여 네트워크를 훈련,
윈도우 생성자 훈련(Windowed Generator Training) 방법을 채용하여 훈련 시간과 메모리 사용량을 줄이기 위해 전체 잠재 표현의 일부를 생성자에 공급하는 방법을 사용.
랜덤으로 크기가 32인 윈도우 세그먼트를 추출→ 디코더에 공급 + 지도학습 모드에서 생성된 멜 스펙트로그램에서 해당 오디오 세그먼트를 추출 → 훈련 대상으로 사용 /4대의 GPU 사용, 배치 크기는 GPU 당 64 + 모델은 800k 단계까지 훈련
- Experimental setup for comparison
: 제1 스테이지 모델로 Tacotron 2(자율회귀 모델)와 Glow-TTS(플로우 기반 비자율회귀 모델)을 사용하고 제2 스테이지 모델로 HiFi-GAN을 사용하여 VITS와 비교.
✨ Results(요약/추출)
* 다른 두 단계 병렬 TTS 시스템인 Glow-TTS와 HiFi-GAN과 합성 속도를 비교 → 우리 모델은 중간 표현을 생성하는 모듈이 필요하지 않기 때문에 샘플링 효율성과 속도가 크게 향상됨.
--
1) 추가적인 입력 조건을 필요로하지 않고 텍스트로부터 직접 원시 파형을 합성하는 방법을 배우고
2) 최적 정렬을 계산하는 대신 MAS(단조적 정렬 검색)라는 동적 프로그래밍 방법을 사용하여 최적 정렬을 찾으며
3) 병렬로 샘플을 생성
*추가적으로, VITS는 조건부 VAE를 도입한 최초의 TTS 시스템! (: 텍스트에서 직접 음성 웨이브폼을 생성)
👽위 논문을 읽으면서 ,,,,,
영어로 된 논문이고, 단어가 무척 생소하여 이를 이해하고 본인의 것으로 만드는 데에 상당한 시간을 쏟아야 했습니다..
그렇지만 위의 논문을 공부하면서, TTS 시스템에서 쓰이는 개념과 구조도,
특히 VITS 이전 모델들의 특징과 이와 비교되는 VITS의 차이점을 파악할 수 있어 유익했습니다.
그리고 이를 통해 저희 프로젝트에서 활용할 TTS 시스템을 본격적으로 구현하는 데에 앞서 많은 기초 지식을 쌓은 것 같습니다 !
'CSE > 캡스톤디자인' 카테고리의 다른 글
| [졸업프로젝트] 리액트- 텍스트를 MP3파일로 변환하고 이를 순차적으로 재생하는 기능의 구현 (0) | 2024.05.21 |
|---|
