
밍경송의 E.B
Transformer(2) - Self-Attention and Multi-head Attention Mechanism 본문
Transformer(2) - Self-Attention and Multi-head Attention Mechanism
m_gyxxmi 2024. 7. 10. 11:03
https://mgyxxmi0219.tistory.com/111
Vision Transformer(Vit) & Vision-and-Language Transformer(Vilt)(1) - Attention mechanism
Transformer 모델은 Translate 문제에서 RNN/CNN을 쓰지 않고 Attention과 Fully Connected Layer와 같은 기본 연산들만으로 SOTA 성능을 이끌어낸 연구로 유명하다. 연구에 참여하기 위해 간단히 공부한 부분에
mgyxxmi0219.tistory.com
에서 이어지는 내용입니다.
How about Self-Attention?
이렇게 Attention 메커니즘이 발전하고 있던 와중, RNN 없이 Attention만을 가지고 언어 모델을 만들어보려는 노력에서 탄생한 것이 바로 앞 글에서 언급했던 Transformer 모델이다.
RNN 모델은 순환 신경망 모델인만큼, 네트워크를 계속 업데이트하기 때문에 연산 효율이 떨어진다는 문제가 있었는데, Transformer 모델을 사용하니 이 부분을 개선할 수 있었다고 논문에서 밝혔다.
그렇다면 transformer 모델의 핵심인 Self-Attention은 무엇이고, 어떻게 동작하는가?
What is Self-Attention?
단어 뜻 그대로 앞서 다룬 Attention을 단어들의 연관성 파악을 위해 자기 자신한테 취하는 메커니즘이다.
그러니까, 위의 경우는 sequence to sequnce 였다면, 이 경우는 동일한 sequence 내 를 의미한다.

Self Attention mechanism을 이용하면, 'it'이라는 단어가 'animal'을 가리킨다는 것을 각 토큰의 유사도를 통해 컴퓨터도 쉽게 이해하도록 만들 수 있다.
How to get an output?
Self-Attention에 대해 이해하려면 먼저, Self-Attention의 입력값이 되어주는 Q, K, V에 대해 알아둬야 한다.
- Q(Query) : 입력 시퀀스에서 관련 부분을 찾으려고 하는 정보 벡터
- K(Key) : 관계의 연관도를 결정하기 위해 Q와 비교하는 데에 사용되는 벡터
- V(Value) : 특정 Key에 해당하는 입력 시퀀스의 정보로 가중치를 구하는 벡터
1. Linear 연산

병렬 연산에 적합한 구조로 만들기 위해 Linear 연산을 거친다.
이때 유의해야 할 점은, Linear layer로 들어갈 때 Q K V는 모두 동일한 입력 시퀀스를 가지지만 학습된 W에 따라, 최종 Q K V 값은 달라진다는 점이다.

2. Attention Score
다음으로, Linear 연산이 끝난 Query와 Key 행렬을 내적하여, Attention Score를 구하게 된다.

Q와 K의 행렬곱은 행렬 간의 유사도를 의미하고, 따라서 Attention Score은 Q와 K 사이의 유사도 행렬을 나타낸다.

그림처럼 두 토큰이 얼마나 유사한지를 유사도 행렬의 값을 통해 확인할 수 있다.
3. Scaling and Softmax func
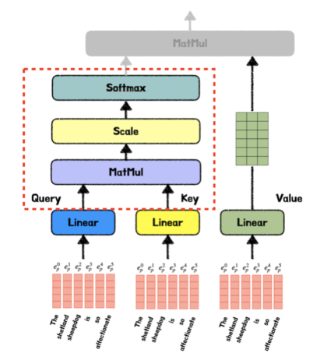
먼저, Scale 연산을 왜 하는지 알아보자.
벡터곱 계산은 문장의 길이가 길 수록 더 큰 숫자를 가지게 되는데, 이것이 뒤에 softmax 함수에 들어가게 되면, 큰 값들 중 특정값만 살아남고 나머지 값들은 죽어버리는 과한 정제 현상이 일어난다고 한다.
따라서, Scale 연산을 통해 softmax 연산이 비슷비슷한 값들 사이에서 수행될 수 있도록 사전 준비를 하는 단계라고 이해했다.
Scale 연산을 수행하기 위해서 Scaling Factor을 이용하는데, 여기서 Factor는 'Dimension of K vector' 즉 '벡터 차원의 제곱근'이다. 만약 행렬의 차원이 4라면 루트 4로 나눠주면 된다.
그리고, Attention score의 유사도를 0-1 사이의 값으로 정규화하기 위해 Softmax 함수를 사용한다.
여기까지의 식을 보면 아래와 같다.

3. Get the Value

끝으로 앞서 구한 Value 행렬을 내적함으로써 Self-Attention Value를 구할 수 있다.
전체 식은 다음과 같다.

Transformer는 위와 같은 Self-Attention을 여러 개 사용하는 'Multi-head Attention'으로 이루어져있다.
What is Multi-head-Attention?


Multi-head Attention은 그림과 같이 Attention을 Head(h) 수 만큼 병렬로 학습시키는 구조이다.
여기서는 도출된 Attention value 값을 concate해서 최종 Attention value를 도출한다. 자세한 식은 생략한다.
그렇다면 Transformer는 왜 이런 방식을 사용하는 것일까?
Why Multi-head?
사실 그냥 그런가보다. , 하고 넘어가려고 했는데 ..이 부분에 대해 잘 정리된 글이 있어서 인용해보자면,
그것은 "병렬로 multi-head를 사용함으로써 여러 부분에 동시에 attention을 가할 수 있는 장점"이 있기 때문이라고 한다.
예를 들면, 한 head는 문장 타입에 집중 하도록 하고, 다른 head는 명사나 동사에 집중 하도록 함으로써 입력 토큰 간의 더 복잡한 관계를 다룰 수 있다고 한다.
이렇게 transformer의 기본 매커니즘에 대해 살펴봤다. 다음에는 진짜 다루고자 했던 Vit(Vision Transformer)에 대해 다뤄보고자 한다.
참고
'DL&ML > model' 카테고리의 다른 글
| CAM(Class Activation Map) 개념 및 논문 정리 (1) | 2024.08.08 |
|---|---|
| Transformer(3) - Vit(Vision Transformer) (1) | 2024.07.12 |
| Transformer(1) - Attention mechanism (1) | 2024.07.05 |


