
밍경송의 E.B
Transformer(3) - Vit(Vision Transformer) 본문
https://mgyxxmi0219.tistory.com/112
Transformer(2) - Self-Attention and Multi-head Attention Mechanism
https://mgyxxmi0219.tistory.com/111 Vision Transformer(Vit) & Vision-and-Language Transformer(Vilt)(1) - Attention mechanismTransformer 모델은 Translate 문제에서 RNN/CNN을 쓰지 않고 Attention과 Fully Connected Layer와 같은 기본 연산들
mgyxxmi0219.tistory.com
에서 이어지는 내용입니다!
이제 Transfomer의 기본 매커니즘에 대해 다뤄봤으니, 궁극적으로 이해하고자 했던 Vision Transformer에 대해 알아보겠습니다.
What is ViT?
Vision Transformer(ViT)는 AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE 에서 발표된 모델로, 기존에 NLP에서 주로 사용되었던 Transformer를 CV에 적용시키려는 노력에서 탄생했다.
논문의 자세한 내용 설명은 생략하고, Vit의 구조에 대해 들여다보자! 전체적인 구조는 아래 그림과 같다.

Text를 주로 다루던 모델이 image를 다루게 하기 위해, 하나의 이미지를 어떻게 input으로 만들었는지 단계별로 이해해보자.
1. 이미지를 패치 크기로 쪼개기 (P*P)

2. 2D의 패치들을 1D 벡터로 Flatten 처리하기 (n*d 배열)

3. 학습 가능한 분류토큰(CLS) 추가하기 ((n+1)*d)

여기서 CLS 토큰이란, input에서 언제나 0-position에 위치한 토큰으로, 다른 input(여기서는 이미지 패치들)과 함께 transformer의 여러 계층을 거치면서, 최종적으로 원래 이미지 전체에 대한 정보를 가장 잘 표현하는 토큰이 된다는 특징이 있다.
그러니까 Sequence data를 Single vector로 변환할 수 있는 아주 간단한 방법인 셈이다. 신기하닷

Bert 모델에서도 CLS토큰을 사용했는데, 물론 image가 아닌 text data지만 어쨌든 Vit는 Bert와 공통점이 참 많다.
Bert에서는 위 그림과 같이 CLS 말고도 문장 구분을 위한 SEP과 같은 토큰도 사용하지만, Vit와는 관련 없는 내용이므로 생략한다.
Bert를 공부하고 Vit를 공부했으면 좋았겠지만 반대로 해보는 것도 좋을 것 같ㅇ다..~ 😎
그리고 Transformer Encoder를 거치고 나오는 CLS 토큰의 값(y)이 output이 되어, MLP Head의 입력으로 들어가게 된다.
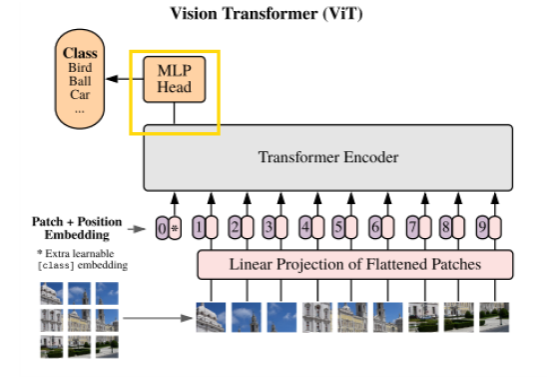
4. 각 패치 임베딩 + CLS토큰에 Position Embedding 벡터 추가

그리고 입력 패치 간의 위치 정보를 임베딩하기 위해 Position Embedding Vector를 추가한다.
이렇게 완성된 일련의 임베딩 벡터들이 Transformer 인코더로 들어가게 된다. 여기까지를 식으로 정리하면 아래와 같다.

이렇게 완성된 input은 인코더로 들어가, 아래와 같은 단계를 L번 거친 뒤 출력된다.

Multi-head attention은 앞선 글에서 다룬 내용이므로 생략하겠다.
Transformer Encoder에서는 Residual Connection & Normalization과 Feed-Forward Layer(그림에서는 MLP로 표현)를 거치도록 되어있는데, 각각에 대해 간단히 이해해보자.
Residual Connection(잔차 연결)
Residual Connection이란 Resnet에서 등장한 개념으로, Residual block을 이용해 네트워크 최적화의 난이도를 낮추는 방법이다. 즉, 학습한 함수에 input 값을 한 번 더해주는 방식인데, 자세한 내용은 이 동영상을 시청해보면 좋을 것 같다.
Transformer에서는 Multi-head attention의 출력값을 입력값과 더해주고, MLP 층의 출력값을 입력값과 더해주는 방식으로 이를 적용하고 있다.

Normalization(정규화)
그리고 각 입력들은 Normalization 과정을 거치는데, 이 과정은 각 레이어의 값들이 급격히 변하는 것을 방지하여 빠른 학습을 이끌어낼 수 있다.
Feed-Forward Layer
논문에 의하면, 그림에서 MLP로 표현된 Feed-Forward Layer는 2개의 MLP layer와 1개의 GELU layer로 이루어진다고 한다.
보통 Feed-Forward Layer는 아래 그림과 같이 ReLU layer를 거치는데, 이 논문에서는 ReLU 대신 GELU를 사용했다는 차이점이 있다.

사실 RELU와 GELU, 잘 몰라서 둘의 차이를 좀 찾아봤다.
What is the difference?
먼저 ReLU는 Rectified Linear Unit의 약어로, 입력값이 양수일 경우 그대로 반환하고, 음수일 경우 0을 반환하는 활성화 함수이다.
한편, DELU는 Double Exponential Linear Unit의 약어로, ReLU와는 달리, 양/음의 값에 대해 모두 지수 함수 형태의 출력값을 반환하는 활성화 함수이다.
ReLU는 음수 입력에 대해 값이 고정되는 문제가 있는 한편, DELU는 음수 입력에 대해서도 값을 살릴 수 있지만, 계산 비용이 증가할 수 있다.
Transformer 인코더를 거치는 식은 아래와 같고, 앞서 말했듯 입력으로 들어간 CLS 토큰이 전체 이미지를 대표하는 출력 y로 나오게 된다.

이렇게 출력된 y(vector)는 MLP head로 들어간 뒤 이미지의 시각적 표현을 특정 class 레이블로 mapping하게 된다.

한편, Multi-Modal(Cross Modal) learning에 대한 연구가 활발하게 이루어지고 있는데 Vit를 이용한 ViLT(Vision and Language Transformer) 모델도 주목해볼 만 하다.

Multi-modal의 learning method에는 종류가 2가지(Single Stream, Two Stream) 존재하는데, ViLT의 경우, text와 image(각 modality)의 임베딩 벡터를 concate해 하나의 input으로 만들어 Encoder로 넣는 Single Stream 방식을 이용한다.
전체 식은 아래와 같고, Vit와 유사하게 Transformer의 마지막 레이어를 거친 시퀀스의 첫번째 인덱스값에 모든 입력에 대한 표현이 포함된다.

Multi-modality learnin에 관심이 있다면, 전체 논문을 한 번 읽어보는 것도 좋을 것 같다!
'DL&ML > model' 카테고리의 다른 글
| CAM(Class Activation Map) 개념 및 논문 정리 (1) | 2024.08.08 |
|---|---|
| Transformer(2) - Self-Attention and Multi-head Attention Mechanism (0) | 2024.07.10 |
| Transformer(1) - Attention mechanism (1) | 2024.07.05 |


