
밍경송의 E.B
<12> 정렬 본문
이 글은 시험이 갑자기 15시간정도 남은 사람이 내용 정리를 위해 적는 글입니다.
*[C언어로 쉽게 풀어쓴 자료구조] 책과 숙영리 교수님의 강의를 참고하여 작성하였음을 밝힙니다.🎅
🎅정렬
: 데이터들을 특정순서로 정리하는 것. (수업에서는 non-decreasing order 위주로 다룸)
예에.. 모든 경우에 최적인 정렬 알고리즘은 없다! -> 정렬할 대상의 개수/ 수행시간/ 가용한 mem 또는 disk 크기 고려 필요
ㄴ평가기준 | 비교 횟수와 이동 횟수의 많고 적음
7가지 정렬에 대해서 다뤄보겠습니다. 빠르게 ..'
1 선택정렬(selection sort) 🎅
초기) 비어있는 왼쪽리스트와 정렬이 필요한 오른쪽리스트
-> 완성) 왼쪽리스트에 정렬된 리스트가 오고, 오른쪽리스트는 비어있는 상태

노란색이 sorted part고 오른쪽이 unsorted part인데,
unsorted part에서 가장 작은 친구를 찾아서(SELECT) unsorted part의 맨 앞 친구와 교환하면 한 라운드 끝!
처음에 헷갈렸던 것은 가장 작은 친구를 그냥 맨 앞에 넣어주는 건줄 알았는데 그 자리에 있는 친구랑 교환! 한다는 거임웅
=> 비교는 unsorted part에서 !
[알고리즘]

[코드]

: 라운드를 거칠 때마다 하나씩 데이터가 제자리를 찾아가기 때문에(맨 앞부터)
for문을 돌 때마다 i ++ 되는 게 = unsorted part는 줄고, sorted part는 늘어가는 !
Q. 데이터셋이 이미 정렬돼있다고 해도 swapping은 일어난다. (n-1번)
🎄시간복잡도는 O(n^2)이고, unstable, in-place sort
*안정성을 만족하지 않음 -> 동일한 키 값을 갖는 레코드들의 상대적인 위치가 정렬 후에 바뀌는 알고리즘

5 30 20 30 10 7
5 7 20 30 10 30
5 7 10 30 20 30
5 7 10 20 30 30 <-- 둘이 순서 바뀜!
2 삽입정렬(insertion sort) 🎅
: 정렬되어있는 부분에 새로운 레코드를 정렬이 유지되는 위치에 삽입하는 과정 반복

*선택정렬은 unsorted part에서 비교가 일어났는데 이건 sorted part를 비교하는군..

: 7을 예로 들면, 8과 비교하는데 나보다 크면 넘어가고, 그 다음에 5랑 했는데 나보다 작으니까 거기에 삽입(INSERTION)
[알고리즘]

*while문에서 나올 때. 마지막으로 비교된 element가 A[j] (A[j]가 key보다 작거나 같은 값)
-> A[j+1]로 들어가야 함.
*만약 key가 A[0]보다 작다(=가장 작은 값)
-> j가 -1이므로(line 6), A[0]에 삽입됨
[코드]

🎄stable, in-place sort
3 버블정렬(bubble sort) 🎅
: 인접한 2개의 레코드를 비교 -> 순서대로 되어있지 않으면 서로 교환하는 방법
각 라운드가 끝날 때마다 가장 큰 데이터가 최종 위치를 찾아감.(맨 오른쪽)

[알고리즘]

[코드]

쩝 버블정렬은 별거 없었..군!
🎄stable, in-place sort
4 쉘 정렬(shell sort) 🎅
: 전체 리스트를 일정 간격(gap)의 부분리스트로 나눠서 삽입정렬을 진행함.
*기존 삽입 정렬은 이웃한 위치로만 이동하기 때문에 이동이 많다는 단점 존재 -> 보완

그 다음엔 gap을 3으로, 다음엔 1로 간격을 줄여서 전체 정렬된 배열을 완성!
[삽입정렬과의 비교 코드]

🎄stable, in-place sort
gap을 어떻게 잡느냐에 따라 복잡도가 좌우된닥
5 합병 정렬 (merge sort)🎅
: 리스트를 균등한 크기로 분할 -> 분할된 리스트 정렬 -> 정렬된 리스트를 합하여 정렬

[알고리즘]

3번에서 계속 재귀호출 --> 요게 끝나야 4번으로 넘어가는 것!
*정렬이 이루어지는 순서,

Q. merge sort 과정 중의 변화하는 list의 상태가 아닌 것은?
Q. 앞 부분이 sorting되지 않은 상태에서 뒤에가 sorting될 수 없음
- 10 12 20 27 13 25 15 22 ( O )
- 27 19 12 29 13 15 22 25 ( X )
Q. 데이터가 2의 제곱수의 개수를 가지지 않으면 어떻게 쪼개질까?

((012))에서 2/2는 1이니까, ((01))까지 먼저 정렬 -> 다음에 ((2)) 정렬.. 요런 거 주의
mid = (left + right) /2
[합병 알고리즘]

*15 line : 두 배열의 개수가 맞지 않을 때는 남은 부분을 바로 복사함(부분 배열은 이미 정렬된 상태라 그대로 복사해도 됨)
*16 line : sorted를 list로 복사해야 일부가 정렬된 list를 그대로 다음 단계에 사용 가능
Ex) 4개씩 정렬된 상태에서 마지막 merge를 진행하는 상황
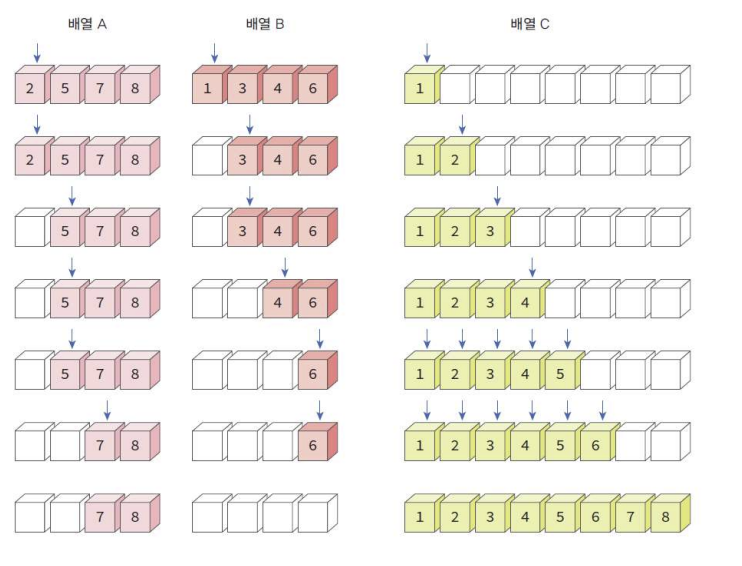
*배열 A와 배열 B의 첫 값부터 비교해서 작은 것 넣기
-> 안 넣은 값은 그대로 두고, 들어간 값이 속해있던 배열의 인덱스만 다음으로 이동해서 또 비교!
*total : n 이라면, n-1 번 비교 + n번의 copy 필요
[코드]

저기 등호가 있기 때문에, 동일한 값이 있을 때 stable하게 정렬이 유지됨! (if 합병하려는 두 배열에 같은 값이 존재할 때 -> 왼쪽에 있는 값이 먼저 copy됨)
🎄stable, Not in-place
6 퀵정렬 (quick sort) 🎅
: pivot(기준점)을 이용하여 리스트를 2개의 부분리스트로 비균등 분할 -> 각 부분리스트를 퀵정렬함

* 한 라운드를 거치면 pivot은 자기 자리를 찾아감! (수업에서는 pivot을 단계마다 가장 왼쪽 값으로 설정)
[알고리즘]

EX)

*low는 오른쪽으로 가면서 pivot보다 큰 친구 찾기, high는 왼쪽으로 가면서 pivot보다 작은 친구 찾기
엇 둘 다 찾았으면 둘이 교환 -> 언제까지? high < low 일 때까지.
= if (high < low) -> no swapping and done + 이 때의 high가 pivot이 들어 갈 위치!
[코드]

*do-while문은 한 번은 무조건 실행됨 -> low에는 pivot값이 있을테니 ++, high를 right+1로 애초에 설정했기 때문에 --를 해주고 시작!
🎄O(n log n) , in-place sort
7 기수 정렬(Radix sort)🎅
: 레코드를 비교하지 않고 정렬 수행. 기수 정렬이 가능하다면 O(dn)의 시간복잡도를 가짐
버킷에 넣었다가 순서에 맞게 빼기만 하면 됨!
*두 자리 수의 기수 정렬 -> 낮은 자리 수로 먼저 분류한 다음, 순서대로 읽어서 다시 높은 자리 수로 분류

*이때 자료구조는 큐를 사용함 ! -> 큐가 아니면 unstable하고, 정렬도 안됨!
[알고리즘]

[코드]

연습!

🎄stable, Not in-place

Q. data type이 실수인 경우, 가장 좁은 정렬의 빅오는 n log n (실수는 기수 정렬 불가)
Q. 100자리 정수인 경우, 기수 정렬이 합병 정렬보다 빠르다 (정수는 기수 정렬 가능)
'CSE > 자료구조&알고리즘' 카테고리의 다른 글
| <11> 그래프2 (0) | 2023.12.14 |
|---|---|
| <10> 그래프 1 (0) | 2023.12.12 |
| <7> 원형 연결리스트, 이중 연결리스트 (1) | 2023.10.26 |
| <6> 단일 연결리스트 (1) | 2023.10.26 |
| <5> 큐(Queue) (0) | 2023.10.26 |



